 从CPU亲缘性探究Thread.currentThread
从CPU亲缘性探究Thread.currentThread
# 从CPU亲缘性探究Thread.currentThread
在美团这篇文章: 《Redis 高负载下的中断优化》 (opens new window)看到了一个叫做CPU亲缘性的东西
如果某个
CPU Core正在处理Redis的调用,执行到一半时产生了中断,那么CPU不得不停止当前的工作转而处理中断请求,中断期间Redis也无法转交给其他core继续运行,必须等处理完中断后才能继续运行。Redis本身定位就是高速缓存,线上的平均端到端响应时间小于1ms,如果频繁被中断,那么响应时间必然受到极大影响。容易想到,由最初的CPU 0单核处理中断,改进到多核处理中断,Redis进程被中断影响的几率增大了,因此我们需要对Redis进程也设置CPU亲缘性,使其与处理中断的Core互相错开,避免受到影响。
在网卡收集到数据包的时候,需要CPU进行一个软中断,告诉操作系统内核有数据进来了。
所以,在大量的网络请求过来之后,可能Redis处理数据的CPU的核心、和响应中断的CPU的核心是同一个核心。
那就意味着,一旦CPU中断了(即使速度很快),也会影响Redis的处理速度。
作者还提到:
由于
Linux wake affinity特性,如果两个进程频繁互动,调度系统会觉得它们很有可能共享同样的数据,把它们放到同一CPU核心或NUMA Node有助于提高缓存和内存的访问性能,所以当一个进程唤醒另一个的时候,被唤醒的进程可能会被放到相同的CPU core或者相同的NUMA节点上。此特性对中断唤醒进程时也起作用,在上一节所述的现象中,所有的网络中断都分配给CPU 0去处理,当中断处理完成时,由于wakeup affinity特性的作用,所唤醒的用户进程也被安排给CPU 0或其所在的numa节点上其他core。而当两个NUMA node处理中断时,这种调度特性有可能导致Redis进程在CPU core之间频繁迁移,造成性能损失。
也就是说,如果CPU核心一直在交替处理Redis和网络请求,那么就会导致没有办法进行有效缓存,进而影响性能。
# 探究
所以从美团的这篇文章上来看,我觉得JVM实际上也会有这样的问题,就突发奇想了一下,如果JVM的线程调度归个类,让相似的线程使用同一个CPU核心处理,这样不就能够进一步加强并发效率么?
然后就查询了各种资料,最后发现有个叫做Java Thread Affinity的东西。
# Java Thread Affinity简介
git地址: https://github.com/OpenHFT/Java-Thread-Affinity (opens new window)
Java Thread Affinity是将Java代码中的线程绑定到CPU特定的核上,用来提升程序的性能。底层使用了JNA技术来提供对底层线程的访问能力
JNA(Java Native Access )提供封装好的java函数用JNI来调用本地共享文件.dll/.so中的函数
在双核的服务器上使用lscpu命令来查看系统的CPU情况,如下所示
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 2
Core(s) per socket: 1
座: 1
NUMA 节点: 1
厂商 ID: GenuineIntel
CPU 系列: 6
型号: 79
型号名称: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
步进: 1
CPU MHz: 2494.220
BogoMIPS: 4988.44
超管理器厂商: KVM
虚拟化类型: 完全
L1d 缓存: 32K
L1i 缓存: 32K
L2 缓存: 256K
L3 缓存: 40960K
NUMA 节点0 CPU: 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt
从上面的输出我们可以看到,这个服务器有两个socket,每个socket有一个core,每个core可以同时处理2个线程。
完整的信息在/proc/cpuinfo中:
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
stepping : 1
microcode : 0x1
cpu MHz : 2494.220
cache size : 40960 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt
bogomips : 4988.44
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
stepping : 1
microcode : 0x1
cpu MHz : 2494.220
cache size : 40960 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 1
initial apicid : 1
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt
bogomips : 4988.44
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
Java Thread Affinity会读取/proc/cpuinfo来确定CPU的layout信息,代码中有个CpuLayout与之对应:
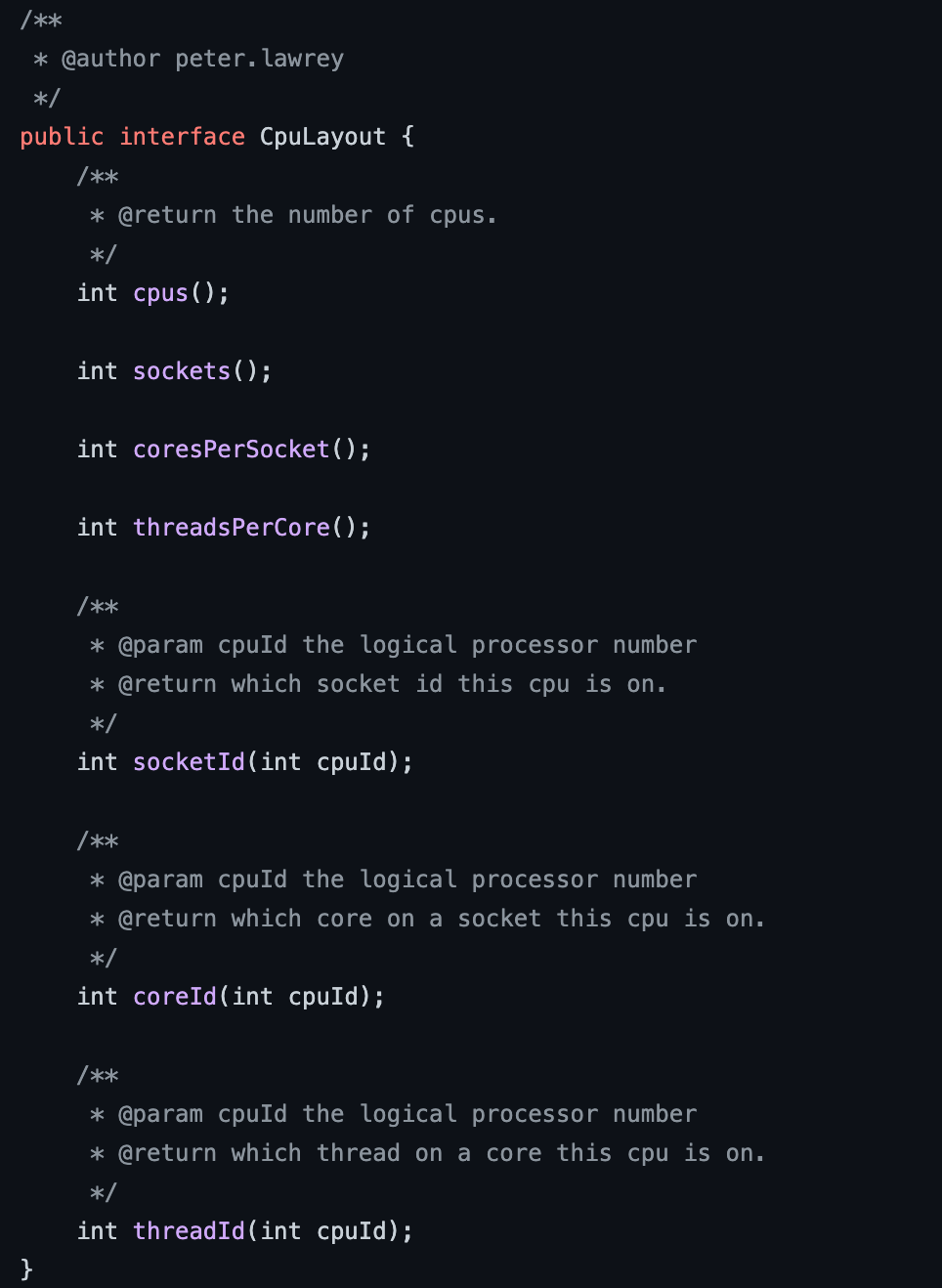
根据CPU layout的信息, AffinityStrategies提供了一些基本的Affinity策略,用来安排不同的thread之间的分布关系:
public enum AffinityStrategies implements AffinityStrategy {
/**
* 任何CPU都行.
*/
ANY {
@Override
public boolean matches(int cpuId, int cpuId2) {
return true;
}
},
/**
* 运行在同一个core中.
*/
SAME_CORE {
@Override
public boolean matches(int cpuId, int cpuId2) {
CpuLayout cpuLayout = AffinityLock.cpuLayout();
return cpuLayout.socketId(cpuId) == cpuLayout.socketId(cpuId2) &&
cpuLayout.coreId(cpuId) == cpuLayout.coreId(cpuId2);
}
},
/**
* 运行在同一个socket中,但是不在同一个core上。.
*/
SAME_SOCKET {
@Override
public boolean matches(int cpuId, int cpuId2) {
CpuLayout cpuLayout = AffinityLock.cpuLayout();
return cpuLayout.socketId(cpuId) == cpuLayout.socketId(cpuId2) &&
cpuLayout.coreId(cpuId) != cpuLayout.coreId(cpuId2);
}
},
/**
* 运行在不同的socket中
*/
DIFFERENT_CORE {
@Override
public boolean matches(int cpuId, int cpuId2) {
CpuLayout cpuLayout = AffinityLock.cpuLayout();
return cpuLayout.socketId(cpuId) != cpuLayout.socketId(cpuId2) ||
cpuLayout.coreId(cpuId) != cpuLayout.coreId(cpuId2);
}
},
/**
* 运行在不同的core上
*/
DIFFERENT_SOCKET {
@Override
public boolean matches(int cpuId, int cpuId2) {
CpuLayout cpuLayout = AffinityLock.cpuLayout();
return cpuLayout.socketId(cpuId) != cpuLayout.socketId(cpuId2);
}
}
}
由于MacOS系统的局限性,没有办法通过/proc/cpuinfo获取到CPU信息,全部都是走的默认NoCpuLayout来进行处理,我的Mac是16核,默认16核全部参与工作。
# 使用方式
- 限制线程在单个CPU核心上运行
try (AffinityLock al = AffinityLock.acquireLock()) {
// do some work while locked to a CPU.
System.out.println(al.cpuId());
while(true) {}
}
- 指定CPU运行
try (AffinityLock al = AffinityLock.acquireLock(5)) {
// do some work while locked to a CPU.
System.out.println(al.cpuId());
while(true) {}
}
- 线程池指定
Affinity提供了线程工厂方法,可以构造自己的线程池的亲缘策略
ExecutorService ES = Executors.newFixedThreadPool(4,new AffinityThreadFactory("bg", SAME_CORE, DIFFERENT_SOCKET, ANY));
# 原理
一般服务器都是Linux的,所以只看Linux下的实现。
Java Thread Affinity有个CLibrary的匿名内部类,用来封装操作系统提供的API
interface CLibrary extends Library {
CLibrary INSTANCE = (CLibrary) Native.loadLibrary(LIBRARY_NAME, CLibrary.class);
int sched_setaffinity(final int pid,
final int cpusetsize,
final cpu_set_t cpuset) throws LastErrorException;
int sched_getaffinity(final int pid,
final int cpusetsize,
final cpu_set_t cpuset) throws LastErrorException;
int getpid() throws LastErrorException;
int sched_getcpu() throws LastErrorException;
int uname(final utsname name) throws LastErrorException;
int syscall(int number, Object... args) throws LastErrorException;
}
sched_setaffinity可以将某个进程绑定到一个特定的CPU,这是Linux提供了设置CPU亲和力的方法。
通过调用这个方法,将cpu的掩码绑定到对应的pid上面,就能够形成亲和。
# 总结
Java Thread Affinity可以从JAVA代码中对程序中Thread使用的CPU进行控制。
能够通过自行设置亲和力的方式,来避免操作系统本身的调度。
- 01
- Jackson配置BigDecimal序列化保留小数点位数03-19
- 02
- elegraph上传图片Image dimensions invalid03-19
- 03
- arm64 版 picgo 提示已损坏解决办法02-19