 4S分析法
4S分析法
# 4S分析法
以Twitter为案例,来作为一个分析
# Scenario场景
需要设计哪些功能
将功能列举出来,并进行排列,因为在一场中不可能让你设计整个系统,只能设计系统中的某几个最重要的模块
需要承受多大的访问量
承载的访问量的大小决定了采用中间件去实现我们的系统,不同的承载量所需要的中间件和设备都是不一样的,所以系统设计并没有最合适的架构,只有在衡量成本和收益之后设计出来的最符合当下情况的最合适的架构
# 需要设计哪些功能
第一步列举功能:
- 注册、登录
- 用户个人页面展示、编辑
- 上传图片、视频
- 搜索
- 发送分享Twitter内容
- TimeLine和News Feed
- 关注和取消关注用户
第二步骤,功能排序,选出核心功能:
- 发送Twitter
- TimeLine展示
- News Feed推送
- 关注和取消关注用户
- 注册登录
# 需要承受的访问量
我们需要对访问量进行一个估算,下面大致是估算方式 :
并发用户Concurrent User
- 日活跃用户数量 * 每个用户平均请求次数 / 一天多少秒 = 1M * 60 / 86100 $\approx$ 700K
- 峰值 = Average Concurrent User * 3 $\approx$ 2100K
读频率Read QPS (Queries Per Second)
- 700K
写频率Write QPS
- 5K
这样就大致分析出需要承载的QPS。
下面是一些硬件或者软件能够承载的QPS数量:
QPS=100
- 笔记本电脑
QPS=1k
- Web服务器
- 需要考虑单点故障
QPS=1m
- 建设1000台的服务器集群
- 需要考虑集群维护成本,如何对资源进行调度
QPS和WebServer 、Database之间的关系
- 一台Web Server承受量是1k的QPS,实际上如果能扛得住100个QPS已经很牛逼了
- 一台SQL Database承受量是1k QPS左右
- 一个NoSQL集群(Elasticsearch)承受量是10W左右
- 内存数据库(Redis)100W QPS左右
通过这些预估的QPS数量,就能够估算出所需要的机器。
# Service服务
将大系统拆分成一个个小服务。
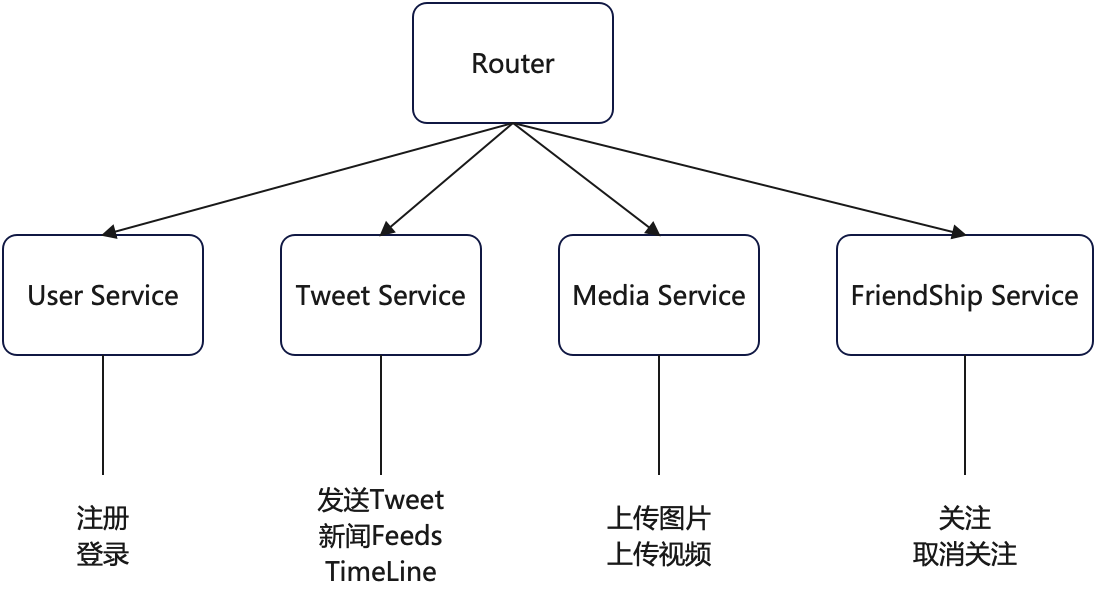
重放需求
重新过一遍每个需求,为每个需求添加一个服务,用于处理内部逻辑
归并需求
归并相同的服务,对同一类问题的逻辑处理归并在同一个Service中
将整个系统切分成若干个小的Service
# Storage存储
对于我们写的Service而言,写的是具象化的程序,而程序=算法+数据结构。
但是对于系统而言,系统=服务+数据存储。
所以确定存储结构和介质尤为重要。
# 处理步骤
# 第一步:为每个Service选择存储结构
数据库系统
关系型数据库 SQL DataBase
- 用户信息
非关系数据库
- 推文
- 社交图谱
文件系统
- 图片、视频、Media Files
缓存系统Cache
- 不支持数据持久化
- 但是效率高,内存级别的访问速度
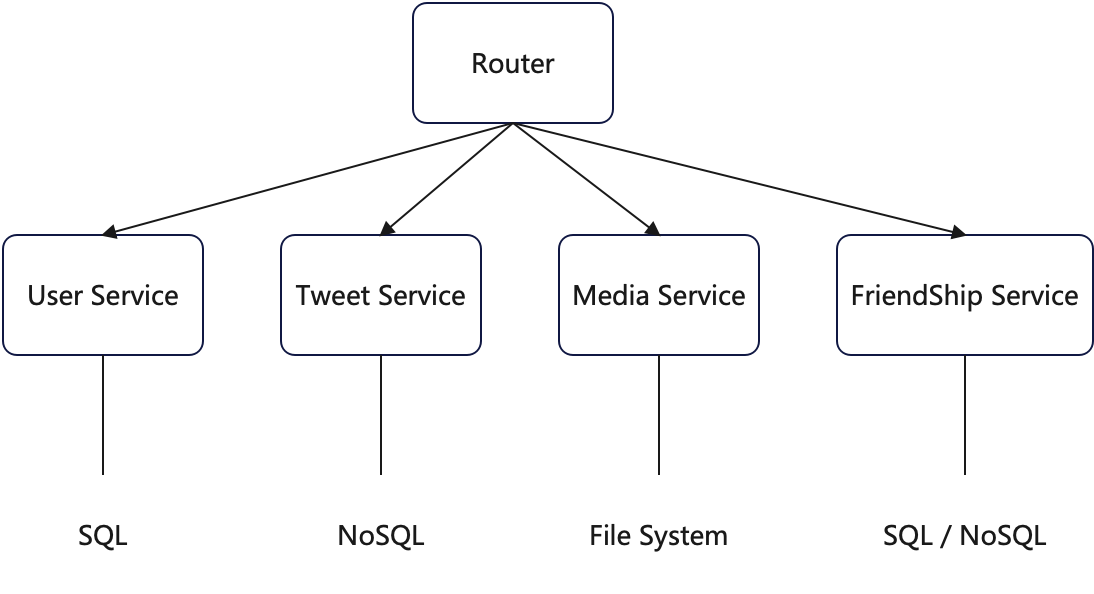
# 第二步:细化表结构
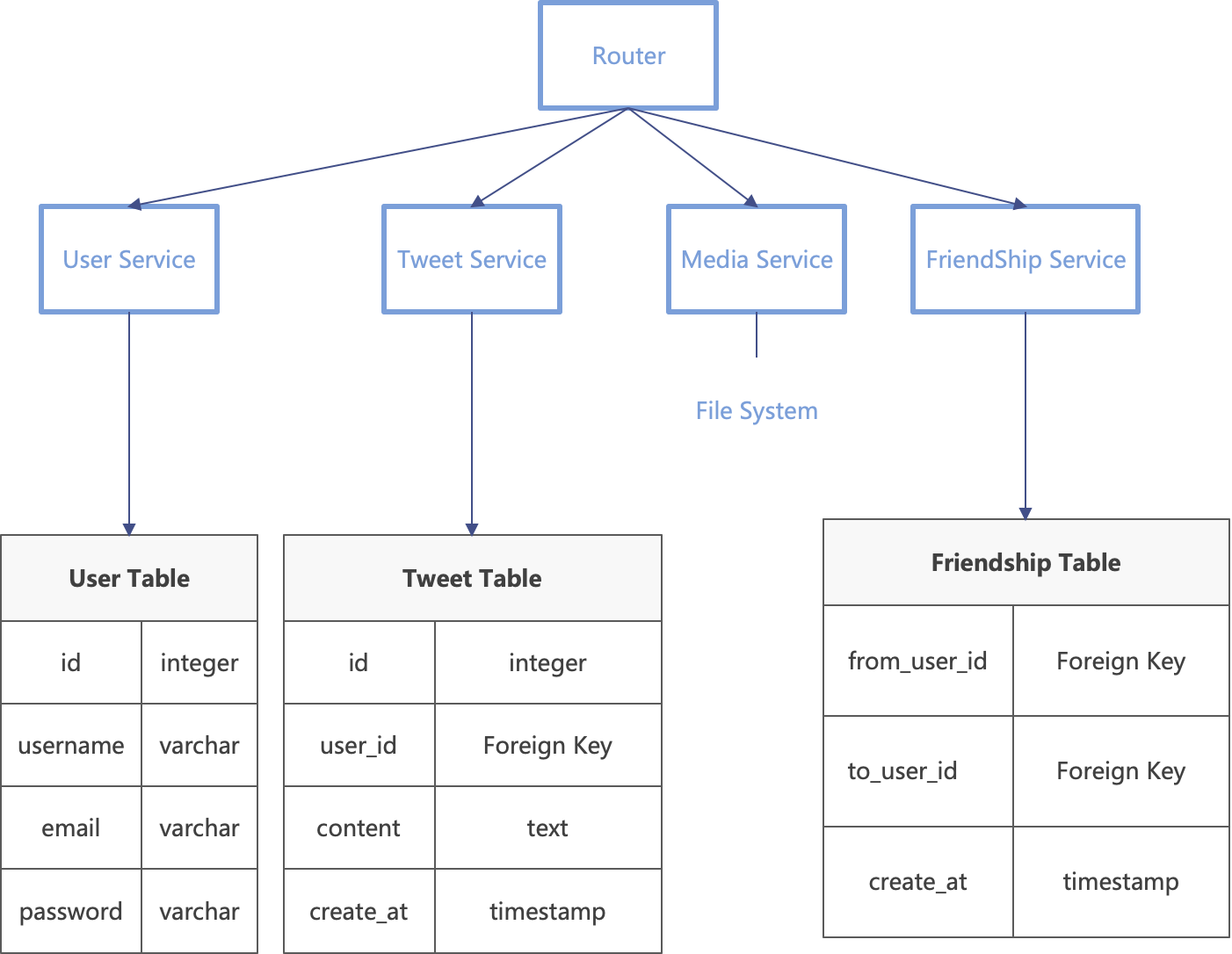
# 存储模型
# Pull Model 拉模型
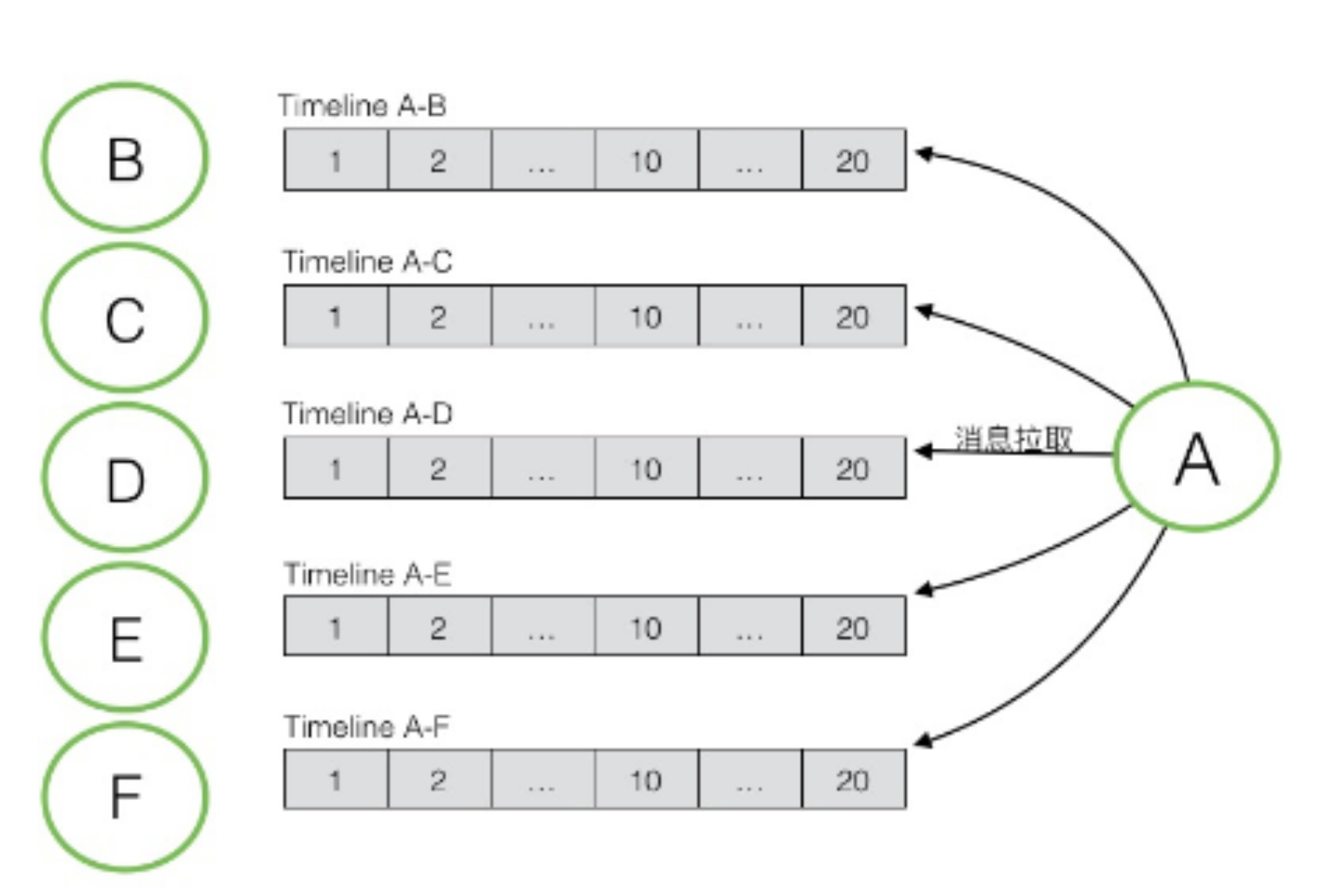
算法:
在用户查看News Feed时,获取每一个好友的前100条Tweets,用K路归并算法进行合并,合并出前100条News Feeds
复杂度分析
- 获取News Feed ,如果有N个关注对象,则为N次DB Reads的时间 + K路归并的时间(可以忽略,因为DB Read花费时间更多)
- 发布Tweet ,1次DB Write的时间
# Scala扩展设计
- Optimize 优化
- Maintenance 维护
# 处理步骤
# 第一步:优化
解决设计缺陷
- Pull 和 Push 模式的局限性
更多的功能
- Like、Follow & Unfollow、Ads
特殊情况
- 僵尸粉、热搜
# 第二部:维护
健壮性
- 服务器或者数据库挂了
扩展性
- 应对流量暴增的情况
# Pull的缺陷
在用户进行读请求时,会访问每个关注的人的DB,所以这一块将会成为瓶颈
在访问DB之前,加入Cache
缓存每个用户的TimeLine
- N次DB请求 转化为 N次Cache请求
缓存每个用户的News Feeds
- 没有Cache News Feed的用户:归并N个用户最近的100条Tweets,取出结果前的100条
- 有Cache News Feed的用户:归并N个用户在某个时间戳之后的所有Tweets
# Push的缺陷
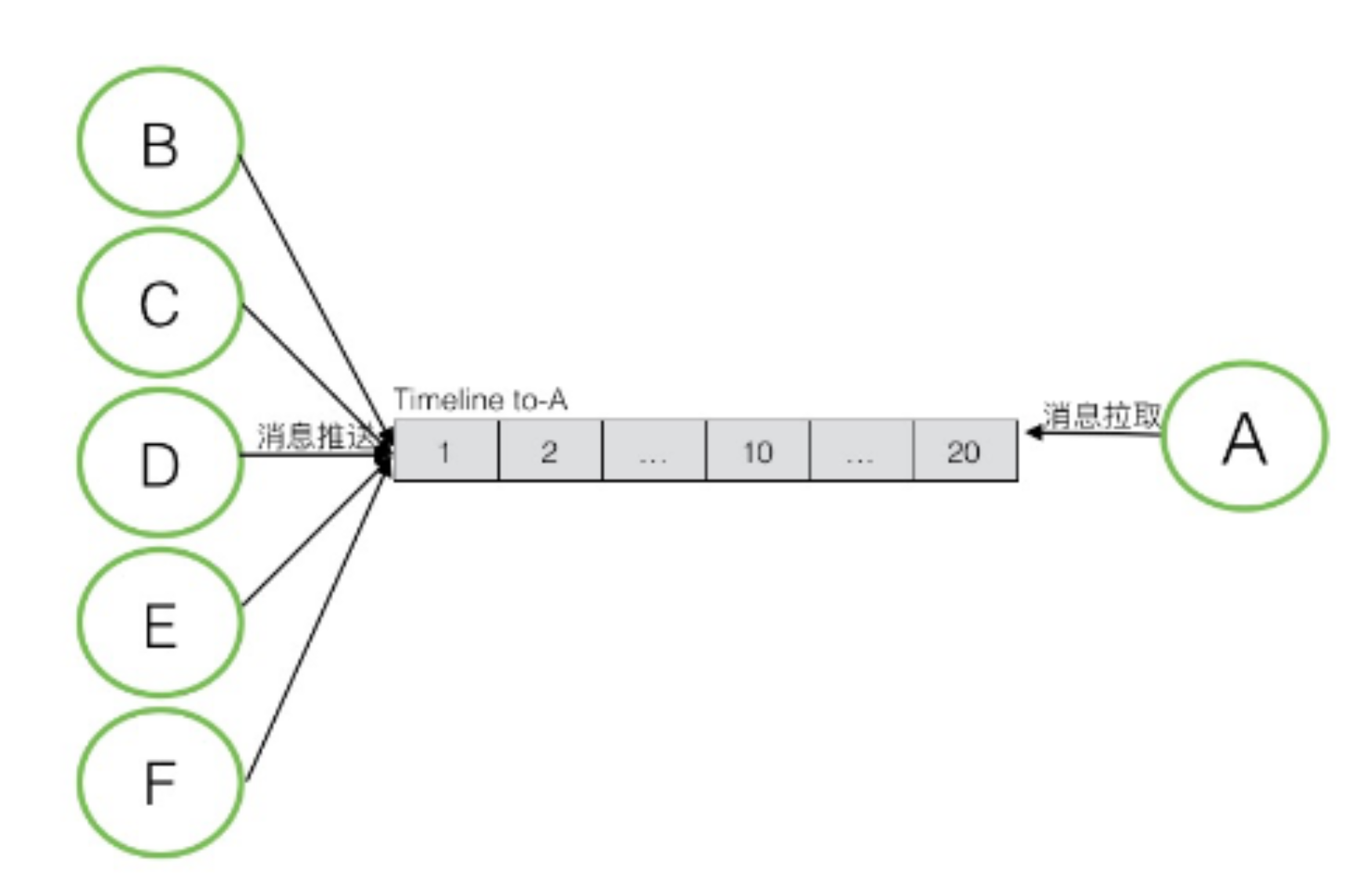
在用户发布一篇文章时,会向关注者的TimeLine中都插入一条Tweets。
会浪费更多的存储空间
- 每个人那都会有一条Tweets数据
- 存储相对内存便宜,可以接受
不活跃用户的问题
- 导致每个人收到的时间不一样
粉丝数量超级大,亿级
- 插入的时长即使异步,也非常慢
- 切换回Pull模式,需要Trade Off : Pull 和 Push成本
# 处理
# 最小改动
扩展机器
- Push的话,将需要插入的Tweets分布到多台机器上,并行插入
- Pull的话,增加Cache容量
# 增长预估
对当前业务量的增长率进行一个预判,衡量是采用Pull还是Push,如果实在太大,考虑Push结合Pull进行优化
- 普通用户使用Push方案进行处理
- 标记大V用户,采用Pull方式进行处理
- 用户查询,合并自己的TimeLine + 大V的TimeLine
相对来说混用的模型实现上会比单纯的复杂。